♦ Stanford University
§ MIT
★ ☆ Equal contributions
Abstract:
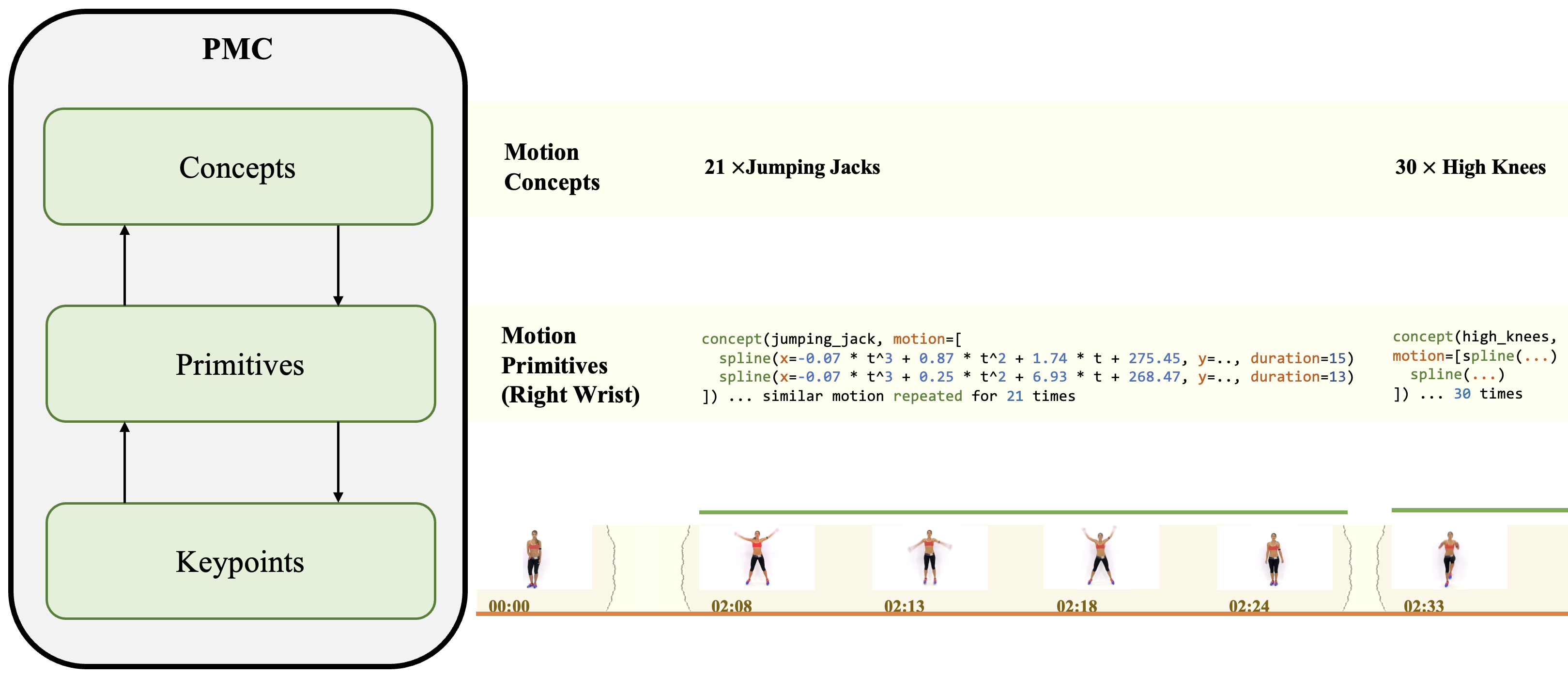
We introduce Programmatic Motion Concepts, a hierarchical motion representation
for human actions that captures both low-level motion and high-level description
as motion concepts. This representation enables human motion description,
interactive editing, and controlled synthesis of novel video sequences within a
single framework. We present an architecture that learns this concept
representation from paired video and action sequences in a semi-supervised
manner. The compactness of our representation also allows us to present a
low-resource training recipe for data-efficient learning. By outperforming
established baselines, especially in the small data regime, we demonstrate the
efficiency and effectiveness of our framework for multiple applications.
@article{motionconcepts2022,
Author={Sumith Kulal and Jiayuan Mao and Alex Aiken and Jiajun Wu},
Title={Programmatic Concept Learning for Human Motion Description and Synthesis},
booktitle={CVPR},
year={2022},
}
Video
Application: Video Description (recognizing and localizing concepts)
Fig. 1: Here the task is to accurately recognize and localize concept instances in an
input video. A visualization of the localized concept intervals for a sample is shown here.
Different colors denote different intervals located by the models. The localized intervals from our model aligns closely with the
ground-truth.
Application: Controlled Video Synthesis (synthesizing from input descriptions)
Fig. 2: Here the task is to generate realistic motion and video sequences by prompting
a description. The input prompt for the above samples is 63 repetitions of jumping jacks. We observe that both the baseline
models produce unnatural motion. On the right is our synthesized video which looks more realistic and representative of the
input description.
Application: Interactive Video Manipulation
Fig. 3: Here the task is to do interactive video manipulation. On the left, we have an
input video and the detected poses and the shown edits have been applied resulting in the output video on right. Here we
perform both low-level edits such as slowing down descent of every repetition and high-level edits such as adding an extra repetition
of jumping jacks and two repetitions of different concept high knees.
Acknowledgements:
We thank Shivam Garg, Maneesh Agrawala and Juan Carlos Niebles for helpful discussions. This work is in part supported by a Magic Grant from the Brown Institute for Media Innovation, the Toyota Research Institute, Stanford HAI, Samsung, IBM, Salesforce, Amazon, and the Stanford Aging and Ethnogeriatrics (SAGE) Research Center under NIH/NIA grant P30 AG059307. The SAGE Center is part of the Resource Centers for Minority Aging Research (RCMAR) Program led by the National Institute on Aging (NIA) at the National Institutes of Health (NIH). Its contents are solely the responsibility of the authors and does not necessarily represent the official views of the NIA or the NIH.}